
基本信息
- 论文: P4 P5 以及 P6
- 作者: Jianping Kelvin Li 和 Kwan-Liu Ma
- 来源: TVCG 2018 (P4), VIS 2019 (P5), and VIS2020 (P6)
UCD马匡六老师组Jianping Kelvin Li的三篇接续工作,虽然关注内容不一样,但写作风格比较相似,都是做这种工具式的东西,值得自己模仿;
P4: Portable Parallel Processing Pipelines for Interactive Information Visualization
P4的目的是实现一个信息可视化的 Portable (轻便的) Parallel (并行) Processing (处理) Pipelines (管道)。
因为现有的可视化工具在expressiveness和high performance之间存在gap,于是作者期待能够开发一种工具,能够使用GPU的计算性能来加速信息可视化的处理和渲染。其提出了四个目标:
- performance:性能(数据处理性能和可视化渲染性能)
- productivity:生产力(不懂GPU编程的人也能用,提供 JSON 格式接口)
- programmability:可编程性(懂的人能编写自己的逻辑,提供 JavaScript 接口)
- portability:轻便性(面向浏览器)
它的contribution是:with declarative grammar to leverage GPU computing for accelerating both data transformations and visualziations
对于data transformation (数据转换)而言,坐着定义了一些原子操作:
- Derive - 从已有属性用自定义逻辑导出新属性
- Match - 保留复合所有指定条件的数据
- Aggregate - 根据指定属性和统计方法进行 聚集(group)/ 装箱(bin)
而对于可视化的可视映射而言,则定义了
- 形状:circle, line, and rectangle
- 通道:color, opacity, width, height, 以及 position x and y
最后还有交互:click, hover, brush, zoom, or pan
以上的这些操作都可以在GPU上完成,具体做法是把以上的这些操作拆分为底层GPU的实现,底层GPU实现分成四种基本操作:
- fetch (key => value): 通过fetch来找到对应某个属性的value
- map
- filter
- reduce
比如derive就可以通过fetch+map的组合进行实现,具体不再详述,只描述一个理念。文章还支持自己实现一些用户逻辑,但感觉写的语言应该是webgl的shader,不太容易;
为了说明GPU对于可视化而言能做的事情,作者还举例了一个感官增强的例子,也就是用透明度来展示密度:
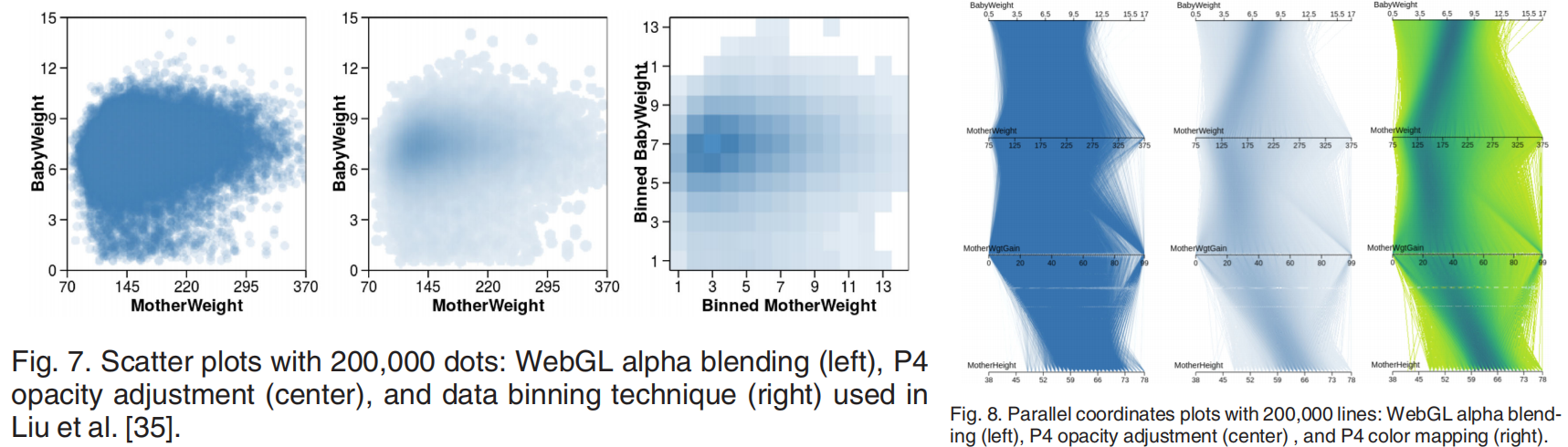
这种操作其实就是核密度估计,可以被用于GPU的操作。
P5: Portable Progressive Parallel Processing Pipelinesfor Interactive Data Analysis and Visualization
渐进式可视化(progressive visualization)属于一种逼近正确可视化结果的一种操作,通过每次操作部分数据,不断累加可视化结果,放弃部分精准度来增加可视化速度,算是一种在computation latency和quality之间的权衡。渐进式可视化特别适合大数据的可视化,其动机也和P4用GPU处理数据的动机是吻合的。
对于这一项工作,作者提出了三个goals:
- Progressive Parallel Processing: 渐进式的并行处理(GPU)
- Declarative Progressive Visualization: 有声明式语法
- Interactive Progressive Analysis: 交互
该工作的贡献是:
- 无缝衔接GPU计算和渐进式处理的可视化框架:a visualization framework that seamlessly integrates GPU computing with progressive processing
- API很直观的渐进式数据转换和可视化声明式语法:an intuitive API with declarative grammar for specifying progressive data transformations and visualization operations, both of which effectively run on the GPU
与传统的可视分析流程不同,渐进式可视化的分析流主要包含了一个划分、批处理、再整合的结果(下图左);本文提出的可视分析详见右边:其主要改变在于它可以提供批量加载数据,并且提供对于每个批次的操作(batch),对于中间结果的操作(progress),以及对于流程的控制(excute next)。
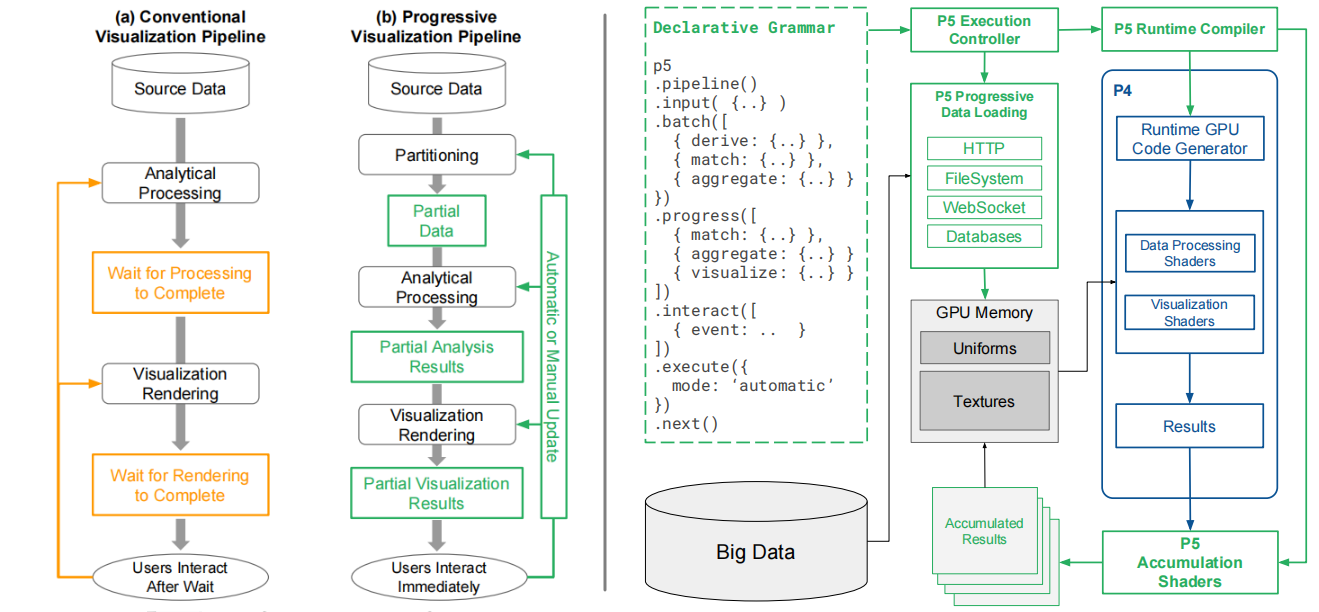
batch操作符指定每个批次的统计计算和数据转换操作,自动累加batch的计算结果,产生中间结果;progress操作符指定对于中间结果的数据转换和可视化操作;- 还拥有一系列对于流程的信号和控制进行回馈的操作符:
executepauseresumeonEachonComplete
下面是例子:
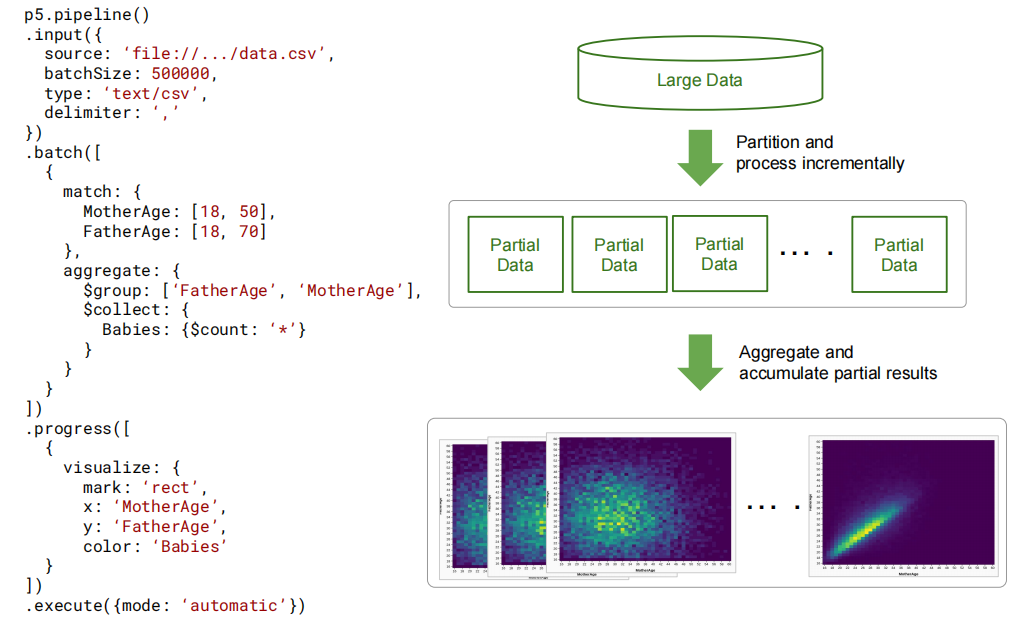
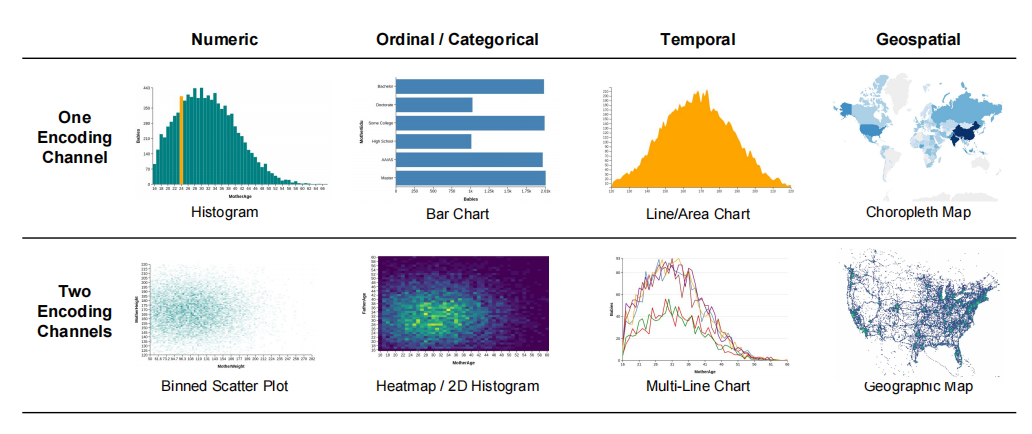
对于可视化而言,作者认为并非所有的可视化形式都适合渐进式可视分析,只选取了 numeric / categorical / temporal / geospatial 四大类。并且,对P4中的多视图可视化做了一些调整和升级。
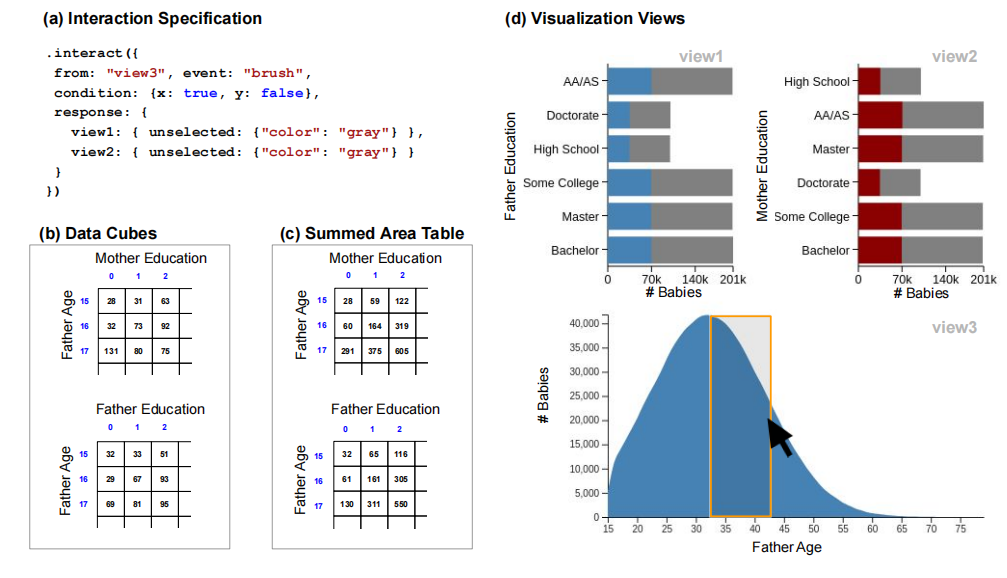
对于交互而言(主要是brush的选择操作),渐进式可视化对于很多统计类型的图表无法操作到具体的细节数据元(如tabular数据的每一行),所以里面用到了累和表来减少对内存的依赖,只需要通过累和表中的cell之间的加减就能得到刷选区域的元素数量。
P6: A Declarative Language for Integrating Machine Learning in Visual Analytics
机器学习和可视分析经常结合在一起用,但缺少一个通用和统一的工具,能够集成两者。作者提出了一个新的框架,设立了三个目标:
- Interactive Machine Learning and Visualization(在界面上交互式调整参数)
- Interactive and Scalable systems(高性能计算(并行计算))
- Declarative Visual Analytics(声明式语法)
他们贡献了一个可以用以集成机器学习和可视化方法的交互式语言(a declarative language for rapidly specifying the design of visual analytics systems that integrate machine learning and visualization methods for interactive visual analysis)
该框架融合了可视分析流程和KDD流程,左边是传统的可视分析流程(将数据进行转化和可视映射,然后绘制成视图),上方则是KDD(知识和数据挖掘)的流程。
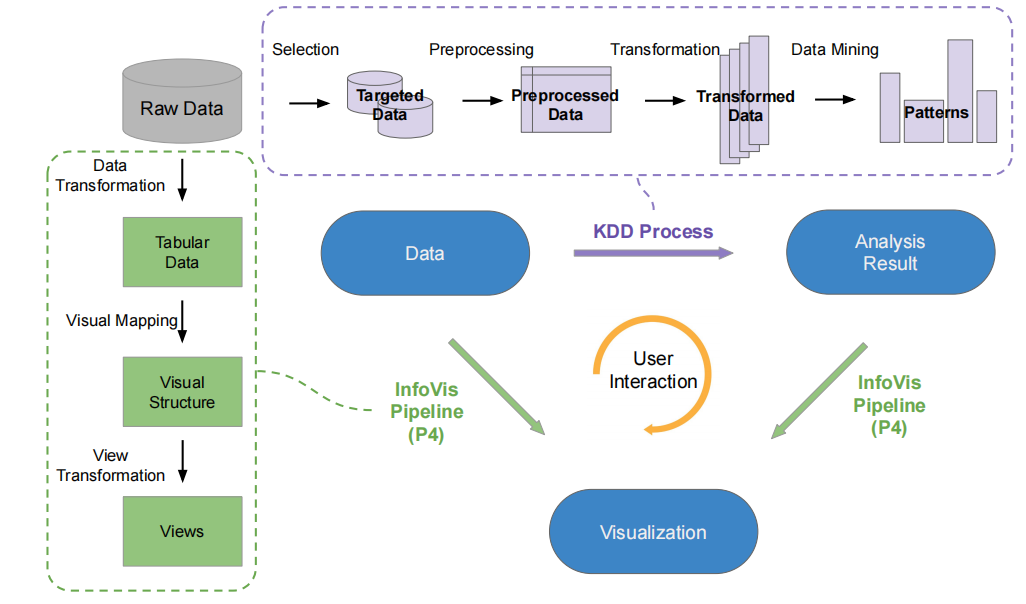
文章主要对这个流程进行了剖析,首先是pipeline:
整个分析流,需要依赖数据(data),分析(analyses),视图及其布局(view-layout),可视化(visualizations)以及交互(interactions);
其中数据(data)又依赖这几项:数据源(source),选择(筛选部分数据,selection),预处理(preprocessing)以及转换(transform);preprocessing主要进行数据清洗、类别型数据的one-hot encoding等,而transform则主要指的是对数据的聚合、过滤、排序等。
分析(analysis)则主要指数据挖掘算法进行挖掘,其中features表示选择的数据属性,scaling则是数据缩放(比如进行标准化),algorithm指挖掘模型,用户还可以通过model训练一个algorithm:
文章主要集成了一些分类、回归等经典的机器学习模型,对原有的多视图语法稍微进行了修改,还能整合多个可视化形式。

作者还支持了模型调参,主要是通过grid search进行参数搜索,还有对于模型选择的属性的一些可视化结果的展示。这个项目并非全部在前端集成,而是一个BS系统,通过python和P4分别执行机器学习和可视分析。